
 News News |
FAQ
|
| Search
|
Home
|
| Getting Started | Documentation | Glish | Learn More | Programming | Contact Us |
|
| Version 1.9 Build 1367 |
|



We have seen how the relation AI = D can describe the measurement
equation of a telescope. This suggests that we think of AI = D as the
Imaging Model. How is the Imaging Model to be used in a deconvolution
algorithm? Many algorithms perform a least squares fit of a model to
the data. For example, CLEAN does least squares fitting of sinusoids to
the visibility data, while MEM does least squares fitting augmented by
an entropy term. The ![]() term can be written as:
term can be written as:
|
|
(8) |
where w is inverse of the covariance matrix of errors. Often the errors are independent between data points, in which case w is diagonal with elements:
|
wi, i = |
(9) |
There are two closely related approachs to using ![]() . First, we
consider an approach based upon the idea of optimization: many
iterative algorithms update an estimate of I based upon
. First, we
consider an approach based upon the idea of optimization: many
iterative algorithms update an estimate of I based upon
![]() and its gradient with respect to I:
and its gradient with respect to I:
|
|
(10) |
We can define the services of the Imaging Model which are required evaluate this term:
The second approach is based on the normal equation. At the optimum
solution I, the gradient of ![]() must be zero and so we have that:
must be zero and so we have that:
| ATwAI = ATwD | (11) |
Note that in imaging, the normal equation sometimes becomes the convolution equation.
Only in rare cases can the normal equation be solved exactly and only in even rarer cases is it a good idea to do so (see Press et al., 1989). Often a better strategy is to make corrections to a trial image based upon the residual in this equation ATwAI - ATwD.
The normal equation probably warrants a service: residual, returning
![]() and
ATwAI - ATwD (which is also, conveniently,
and
ATwAI - ATwD (which is also, conveniently,
![]()
![]() ).
).
Some readers may feel that the distinction between these two approaches is subtle to the point of vanishing. Perhaps the best reason to make such a distinction is that the literature does. Both views are seen in published papers. The normal equation approach looks a bit simpler and avoids the worrying connotations of optimization theory. The optimization approach is more easily improved: for example, one could use conjugate gradients or variable metric algorithms for the optimization. In the rest of this document I will retain the distinction, principally to respect the original derivation of each algorithm.
Following Holdaway and Bhatnagar (1992), I will use the term Imager to denote any algorithm which estimates I from A and D and any extra information. Many existing Imagers fit one of these two approaches:
|
I(n + 1) = I(n) + |
(12) |
where ![]() is the projection operator. In some cases, it pays to
apply the inverse of the diagonal terms of the Hessian:
is the projection operator. In some cases, it pays to
apply the inverse of the diagonal terms of the Hessian:
|
I(n + 1) = I(n) + |
(13) |
A simple example would be to increment the current estimate of I by
the positive parts of the normal equation residual. The operator ![]() then just passes the positive parts of the image. CLEAN is a POCS
algorithm in which the projection operator just passes the maximum
pixel. You may think that POCS is a fancy term for something quite
obvious but there is a convergence proof and other mathematical
machinery which is quite useful: see Youla (1974).
then just passes the positive parts of the image. CLEAN is a POCS
algorithm in which the projection operator just passes the maximum
pixel. You may think that POCS is a fancy term for something quite
obvious but there is a convergence proof and other mathematical
machinery which is quite useful: see Youla (1974).
|
I(n + 1) = I(n) + |
(14) |
where ![]() and
and ![]() are carefully chosen constants.
are carefully chosen constants.
I(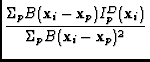
|
(15) |
where IDp is the dirty image for pointing position ![]() and the
summation is over all pointing centers. This algorithm has two uses,
first for low SNR images where the sidelobes of the synthesized beam are
unimportant, and second for adding residuals back to the result of non-linear mosaic.
and the
summation is over all pointing centers. This algorithm has two uses,
first for low SNR images where the sidelobes of the synthesized beam are
unimportant, and second for adding residuals back to the result of non-linear mosaic.
In all these Imagers, the Imaging Model is separated out in a very clean way. For example, MEM needs only to call two services of the Imaging Model: residual and Hdiagonal. An interesting question is whether all Imagers call Imaging Models directly. The only possible exception is the Högbom CLEAN where the point spread function ATwAIP is cached and used in an inner loop. This split is really a semantic one only since one could envisage a program which took a visibility dataset and made the dirty image ATwD and the dirty beam ATwAIP directly and then proceeded to the CLEAN step without writing either to disk. We therefore conclude that in essence all Imagers call upon services of Imaging Models. In some case, many different Imaging Models can be invoked. For example, the non-linear mosaic algorithm can potentially call the residual service of many different Imaging Models: Interferometric, Total Power, Beam-Switched Total Power, etc.
Note that as well as being able to compute the effect of A, we also need to be able to compute the effect of the transpose of A. This is usually quite straightforward and computationally efficient.
|
ATj, i = B( |
(16) |
|
ATj, i = e-j2 |
(17) |
|
ATj, i = B( |
(18) |
|
ATj, i = B( |
(19) |
|
ATj, i = B( |
(20) |
|
ATj, i = B( |
(21) |