News News |
FAQ
|
| Search
|
Home
|
| Getting Started | Documentation | Glish | Learn More | Programming | Contact Us |
|
| Version 1.9 Build 1556 |
|




The underlying raw data for both radio interferometry and single dish is often both quite complex and quite voluminous. Moreover the access patterns users and programmers desire is often quite demanding.
AIPS++ has chosen tabular interface as the fundamental interface to data. Tables in general have been a very successful data type in many astronomical data processing systems (AIPS, IRAF/STSDAS, Midas). Tables are also widely used in FITS for non-image data. The AIPS++ Table interface, as described in the next section, is similar in spirit, although considerably different in detail, than these others.
We have separated out from the Table interface exactly how the bytes are staged from disk (or, indeed, from elsewhere). Indeed, a given table can have different parts which are handled separately. The details about this separation are described in the section on Data Management (section 4.2). This separation of the data interface from the details of its implementations allows us to use different (possibly data dependent) I/O strategies, which the user of data need not be aware of (the creator of the data needs to set up the strategies that seem to be appropriate).
An AIPS++ table consists of a header, and a main data table.
The main data table consists of a number of rows and columns. A value is stored at the intersection of each row and column. All values in a column must be of the same type.
The header consists of a set of keywords. A keyword is a named value (``keyword=value'' pair). Keywords can either be associated with an entire table (e.g., general information about the observation) or with a particular column (e.g., units for the values in the column).
A value is normally one of the following types (see Virtual columns in section 4.2.2 for a generalization):
Note in particular that any value which may be stored in a column, may also be stored in a keyword. Thus one can, for example, store a rotation matrix in a single keyword rather than having to encode it in multiple keywords.
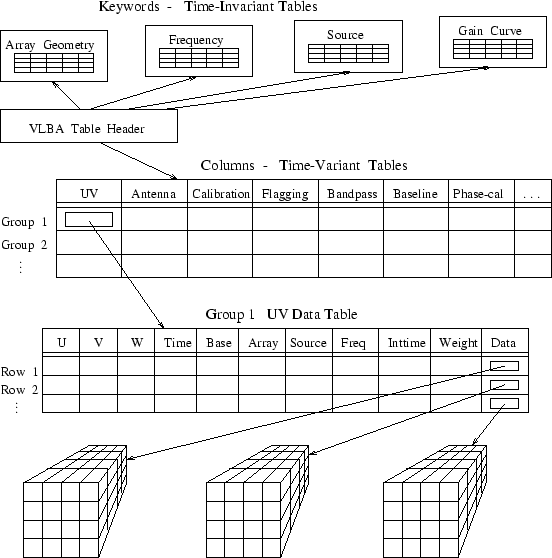 |
An array or table may either be stored directly or indirectly. A direct array or table is embedded directly in its containing table; when in a column, a direct array or table must have an identical structure on each different row12 An indirect array is stored externally to the enclosing table, and its shape (and hence dimensionality) may vary from row to row.13 Similarly, an indirect table may vary in structure from row to row; moreover, an indirect table may be referred (indirectly) from multiple tables. Figure 4 illustrates a possible decomposition of VLBA data into AIPS++ Tables.
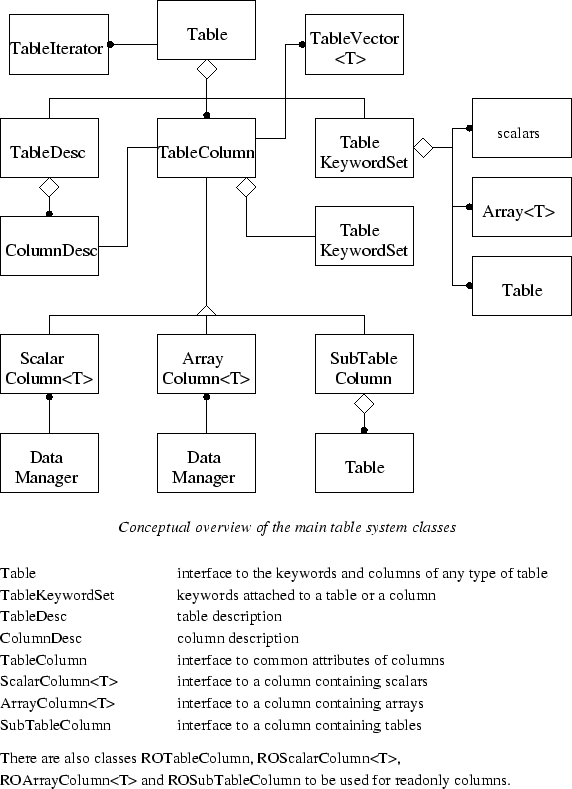
Figure 5 gives an overview of the main table classes. There are classes used to:
The structure of a table is described by a table descriptor. A table description can be used to create new tables (i.e., with no rows). Thus a table description can be used both as a template for creating new tables, and for describing the structure of existing tables. Note that in using a table description as a template, it only describes the minimum of what a table must have, additional columns and keywords may be added.14
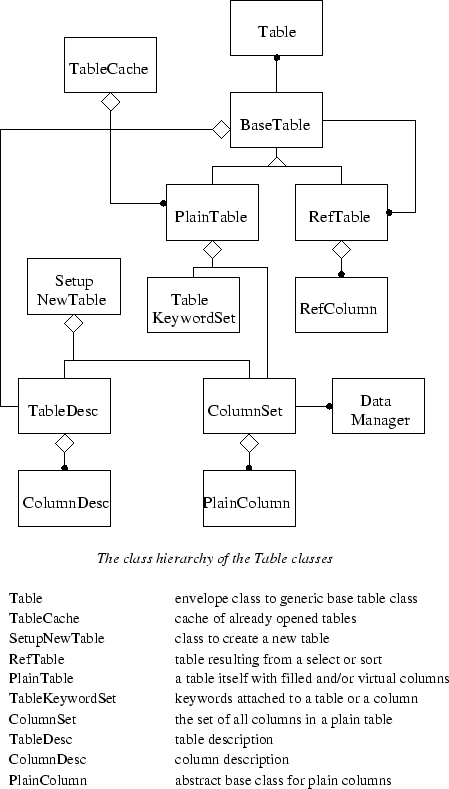
It needs to be emphasized that the Table is an interface to data. The actual data may exist on disk in some files. However, it might also exist in some other underlying table objects, or it might be computed on-demand via some computation when the user requests it.
For example, the data might be stored on disk as 16 bit integers, and ``decompressed'' into floating point for the user. Or, a column might perform an on-the-fly calibration for the user.
Tables where the data are available from files in the normal way are referred to as ``filled'' tables. Tables and columns in which some of the data are computed (or come from some other source) are known as ``virtual'' tables or ``virtual'' columns. This usage of ``virtual'' is probably unfortunate, though descriptive, given the common C++ meaning of that term. The mechanisms by which virtual columns are created are described in section 4.2 below.
A particularly important type of virtual table is one in which all the data is actually in another table. This is known as a reference table. Essentially the reference table has an association with another table, as well as an ordered list of row numbers which map the other table's rows into row numbers of the reference (i.e., virtual) table.
Reference tables are most commonly formed as the result of:
``All rows where column `Flux' is >= 0.'' Both a C++ set of classes and a grammar exist for performing selections. Both logical operations and arithmetic are supported.
The table can be sorted using multiple columns as primary, secondary1, secondary2, etc keys (in ascending or descending order).
A reference table is thus a new view of an existing table. If the reference table is modified, the underlying data in the original table is changed. While this is normally what is wanted, a reference table may be deepened by making a physical copy if desired.
Another important type of virtual table is the iterator table. One often wants to iterate through a table with a ``cursor'' which is a smaller table than the original (fewer rows and columns). Once the iterator is formed, the columns viewed remain constant. However the rows which are seen change as the cursor is moved through the underlying table. Commonly, a table iterator is used to read through data grouping rows in some specified order, for example, all rows with a given time or baseline. Note that the rows which are contiguous in the iterator need not be contiguous in the underlying table.15
Often one might want to perform calculations using entire columns. One approach would be to merely read the column into a one-dimensional array and then calculate normally using the available functions which calculate on arrays.
However this is somewhat unsatisfying for the following reasons:
The solution we have chosen to solve this problem is to introduce the TableVector class. It is logically an entire column which can be manipulated as an array (e.g., arithmetic, logical operations, etc). However, it is not (necessarily) entirely memory resident. The addition of two table vectors would result in a buffer sliding through the table. However, this I/O would be entirely hidden from the user.
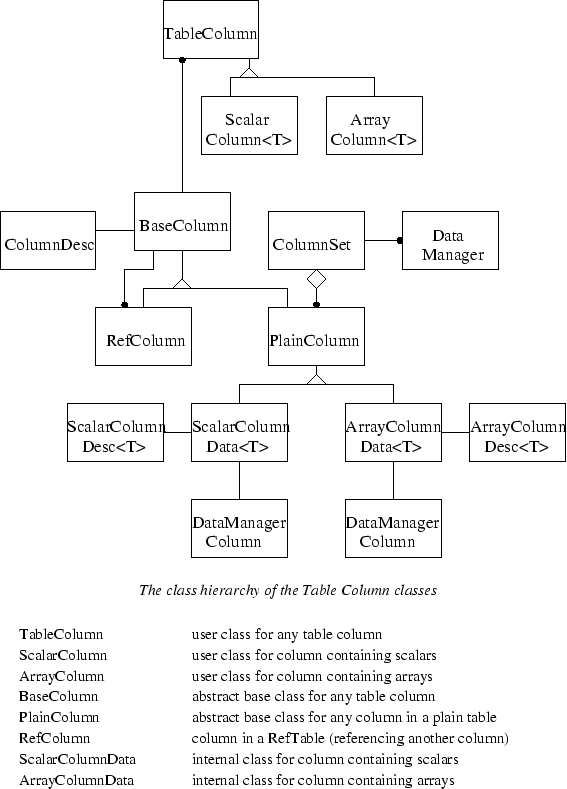
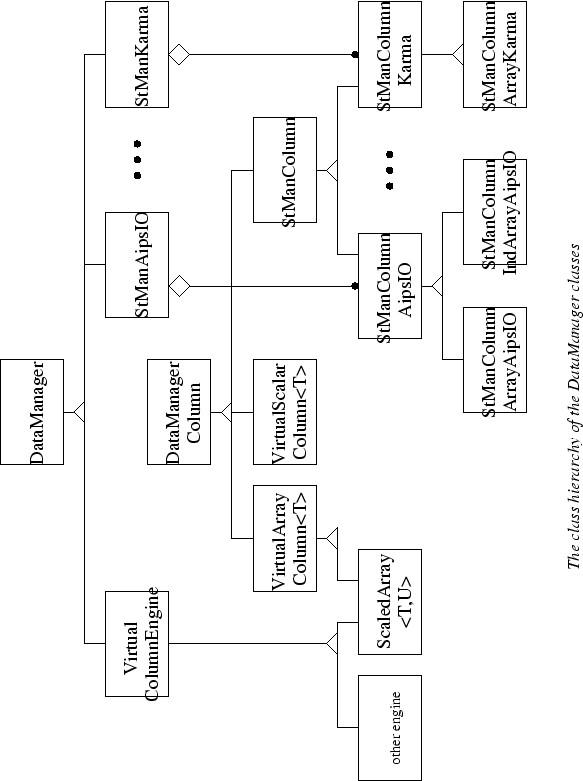
Data is mapped to and from a table interface via data managers. A data manager fundamentally maps ``get'' and ``put'' requests to the implementation data structures (or functions, for virtual columns). Multiple columns are bound to a data manager, and a table may have one or more data managers attached to it. This is an important part of the design: it allows a single table to have multiple types of underlying I/O (presumably tuned for data dependencies) or virtual columns attached. The classes which are involved in attaching columns to data managers are shown in figure 7.
While the Data management layer is below the level at which table users are required to be knowledgable, it is a level which developers who (particularly) need to add additional types of virtual columns need to be aware.
The creator of a table may also need to be aware of the different types of storage and data managers so he can choose the ones which optimize the access that he foresees.
Data managers which physically store and retrieve values from a storage device are known as storage managers. Besides staging data to and from disk16, they are responsible for canonicalizing it (in particular, to IEEE Big Endian) so that computers with different word formats can access the data.
There will be several different types of storage managers in AIPS++, each with different properties. The ones which are either presently implemented or which are being implemented are:
It should be clear that all of the above have different performance and access requirements.18 This lets the table creator choose tradeoffs that he feels are appropriate. No software to automatically migrate from one storage manager to another exists yet (short of a physical copy of the table).
Within this framework, virtual columns may be readily constructed. The only thing that is required is the creation of a so-called VirtualColumnEngine, which is merely a protocol for storing and returning values given a column and a row number.
The first virtual column engine which has been implemented is one in which values of one type are scaled to values of another type via a simple new = old x scale + offset calculation. For relatively low signal to noise data, it can make sense to ``compress'' floating point data down to short integers (for example). However this compression is an optimization that the consumer of the data does not need to be aware of; he just computes normally on his floating point data.
Virtual columns have one capability that filled columns do not: they may contain any type, not just the scalars,arrays of scalars, and tables which may be stored directly.
The design of the AIPS++ Table Data System was initially formulated by A. Farris of the Space Telescope Science Institute, and implemented by G. van Diepen of the NFRA (and also kindly supplied the figures in this section).
The classes and functionality described in this section are entirely implemented with the following exceptions:
Besides finishing the above items, future work will involve such things as I/O optimizations, and improving the ability of end users to directly manipulate tables.