
| Version 1.9 Build 1556
|
|





Next: Example Header File
Up: Documentation
Previous: Document Generation
Subsections
This appendix has the document type definition for the comment markup
language. It is written in SGML syntax. The DTD defines
``elements'' and ``entities''. The elements are the lowest level of
granularity with which SGML deals. The entities function much
like macro; entity references are replaced by the ``body'' of the entity.
There are two basic kinds of entities, general and parameter. The primary
reason a distinction is drawn between these two types of entities is so
that the general entity name space is unique from the parameter entity
name space. Parameter entities are typically used by the designer of the
DTD. As a result, parameter entities are typically used within
other entity or element definitions. This leaves the person writing a
particular document free to use any names when defining general entities.
Entity definitions begin with ``<!entity''. So the definition of a general
entity might look like:
<!entity dquot sdata '\{\tt "\}' >
This defines a general entity which can be used to insert ``double
quotes'' into a document. This is done by placing a reference to the
entity in the document, i.e. ``&dquot;''. Here the ``&'' introduces
the entity reference and the ``;'' ends the entity reference. This double
quote entity is defined in terms of the formatting language into which the
SGML document will be translated, in this case LATEX. So these,
entities must be changed for each SGML processor. For a plain ASCII
system, the entity might look like:
<!entity dquot sdata '"' >
Parameter entities are defined and used in much the same way as general
entities. Except that parameter entities are typically used by the
DTD designer. The following is an example of a parameter entity
definition:
<!entity \% bridgecontent "(p$|$warn$|$note$|$code$|$enum$|$list)" >
This defines a entity bridgecontent. The % indicates that this is a
parameter entity instead of a general entity. This parameter entity is
later used to define the elements that a <bridge> element can contain:
<!element bridge - o ((\%bridgecontent)*) >
The %bridgecontent entity reference is replace by the body of the
entity, (p|warn|note |code|enum|list). Element definitions are
introduced with the`` <!element'', as shown above. The element definition
has four fields, the name e.g. ``bridge'', a pair of fields which indicate
if the opening tag and closing tag are optional or required -- an ``o''
indicates that it is optional and an ``-'' indicates that it is required --,
and a field which indicates the contents of the element. The syntax of
the contents field is similar to lex:
- ``*'' - indicates zero or more occurrences
- ``+'' - indicates one or more occurrences
- ``?'' - indicates zero or one occurrence
- ``,'' - indicates a sequence, e.g. (foo,bar) is <foo> followed by
<bar>
- ``|'' - indicates an ``or'', e.g. (foo|bar) means one of <foo> or <bar>
must occur
- ``&'' - indicates an ``and'', e.g. (foo&bar) means <foo> and <bar>
must occur, but in any order
- ``()'' - parentheses provide grouping
So, the <bridge> example above declares a <bridge> element which can in
turn contain zero or more <p>, <warn>, <note>, <code>, <enum>,
or <list> elements. The opening tag is required, but the closing tag is
optional. Elements are the most basic information units handled by SGML.
They serve a purpose very similar to productions in a grammar.
In addition to elements and entities, there are several ``special''
characters which are useful to know:
- &#TAB; - Horizontal tab
- &#RE; - Record end
- &#RS; - Record start
- &#RS;B - Record start followed by one or more spaces and/or tabs
- &#RS;&#RE; - Empty record
- &#RS;B&#RE; - Record containing only one or more spaces and/or tabs
- B&#RE; - One or more trailing spaces and/or tabs
- BB - Two or more spaces and/or tabs.
These ``invisible'' characters are most useful when trying to define
keyboard shortcuts which prevent document preparers from having to enter
all of the necessary tags. For instance, inserting paragraph tags can be
made easer as follows:
<!entity psplit '</p><p>' >
<!shortref pmap "\&\#RS;B\&\#RE;" psplit
"\&\#RS;\&\#RE;" psplit >
This allows one to insert paragraph breaks by entering a blank
line, i.e. a blank line or an empty line.
- <!entity % divcontent @w"(p|warn|note|verbatim|literal| code|enum|list|descriptor|iodev|thrown)">
- <!entity % bridgecontent "(p|warn|note|code|enum|list)" >
- <!entity % pcontent "#PCDATA" >
- <!entity ptag '<p>' >
- <!entity psplit '</p><p>' >
- <!shortref pmap "&#RS;B&#RE;" psplit "&#RS;&#RE;" psplit >
- <!usemap pmap p>
- <!element div - - (title?, divbody) >
- <!element divbody o o ((%divcontent)* | divset) >
- <!element divset o o ((div,bridge?)*, div) >
- <!element bridge - o ((%bridgecontent)*) >
- <!element p o o (%pcontent) * >
- <!element warn - o (title?, #PCDATA) >
- <!element note - o (title?, #PCDATA) >
- <!element verbatim - - (title?, (#CDATA)) >
- <!element literal - - (title?, (#RCDATA)) >
- <!element code - - (title?, (#CDATA)) >
- <!element enum - - (title?, (item*)) >
- <!element list - - (title?, (item*)) >
- <!element item - o ((p*)|div) >
- <!element title o o (#PCDATA) >
- <!element category - o (#EMPTY) >
- <!attlist category lib CDATA "misc">
- <!attlist category sect CDATA "general">
- <!element descriptor - - ((execution|bounded|memory|iterator|persistent)*) >
- <!element execution - o (sequential|guarded|concurrent|multiple) >
- <!element bounded - o EMPTY >
- <!element memory - o (counted|gc|unmanaged) >
- <!element iterator - o EMPTY >
- <!element persistent - o EMPTY >
- <!element cached - o EMPTY >
- <!element concurrent - o EMPTY >
- <!element memory - o EMPTY >
- <!element manage - o EMPTY >
- <!element iter - o EMPTY >
- <!element persist - o EMPTY >
- <!element counted - o EMPTY >
- <!element gc - o EMPTY >
- <!element unmanaged - o EMPTY >
- <!element iodev - - (level?,item*) >
- <!element level - o (os|(#PCDATA)) >
- <!element os - o EMPTY >
- <!element thrown - - (item*) >
- <!entity lt sdata "{
\lt}" >
- <!entity amp sdata "
\&" >
- <!entity dquot sdata '{
\tt "}' >
- <!entity num sdata "
\#" >
- <!entity gt sdata "{
\gt}" >
- <!entity percnt sdata "
\
- <!entity lpar sdata "(" >
- <!entity rpar sdata ")" >
- <!entity ast sdata "
\mch{
\ast}" >
- <!entity plus sdata "+" >
- <!entity comma sdata "," >
- <!entity hyphen sdata "-" >
- <!entity colon sdata ":" >
- <!entity semi sdata ";" >
- <!entity equals sdata "=" >
- <!entity commat sdata "@" >
- <!entity lsqb sdata "[" >
- <!entity rsqb sdata "]" >
- <!entity circ sdata "
\verb+
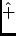 " >
" >
- <!entity lowbar sdata "
\_" >
- <!entity lcub sdata "
\{" >
- <!entity rcub sdata "
\}" >
- <!entity verbar sdata "{
\verbar}" >
- <!entity tilde sdata "
\verb+ +" >
- <!entity mdash sdata "{-{}-{}-{}}" >
- <!entity ndash sdata "{-{}-{}}" >
- <!entity hellip sdata "{
\ldots}" >
Next: Example Header File
Up: Documentation
Previous: Document Generation
Contents
Index
Please send questions or comments about AIPS++ to aips2-request@nrao.edu.
Copyright © 1995-2000 Associated Universities Inc.,
Washington, D.C.
Return to AIPS++ Home Page
2006-10-15
 News
News