News News |
FAQ
|
| Search
|
Home
|
| Getting Started | Documentation | Glish | Learn More | Programming | Contact Us |
|
| Version 1.9 Build 1556 |
|





This section describes the calibration and imaging ``model'' that the AIPS++ project has adopted. This section is only intended to be a relatively brief introduction to the general approach, describing the top level classes. If more detail is required than is available in this overview, see [#!noordam:uvci!#] for radio interferometry, and [#!garwood:sdci!#] for single dish.
Radio telescopes are very inhomogeneous in their characteristics, and hence in the data that they produce. While the differences between a radio interferometer9.5 and a single dish are the most striking (the fundamental data from an interferometer is from the Fourier (pupil) plane, from a single dish, the image plane), every instrument has different characteristics that are reflected in the underlying data ``form'' and values. For example, some instruments observe linear polarizations, others circular, some interferometers observe all baselines in lock-step, others can observe at baseline-dependent rates. More important than the ``form'' of the data, the operations which can be performed on it vary widely: calibration of a connected-element interferometer at low frequency is very different than calibration of a VLBI experiment at high frequency -- the connected element interferometer can probably count on phase stability, but it may also ``see'' that the sky is not flat and need to may use more sophisticated imaging algorithms.
The situation for single dish telescopes is no simpler. Perhaps because a detector for single dish is only needed on one antenna, not on many, instrumentation innovation on these telescopes has been high; for example, multi-beam receivers are becoming common. Moreover, single-dish observers usually observe more interactively than interferometrists have in the past, interactively reducing their data and steering their ongoing observations.
Next generation interferometry instruments such as the Millimeter Array (MMA) will combine many of the above characteristics.
The challenge for a software system that wants to be able to deal with more than one of the above telescopes, let alone all of them, is daunting. It must be capable of exploiting the unique features any particular telescope might have, while providing common tools that operate as widely as possible.
The approach described here was invented at a workshop in Green Bank, West Virginia, in early 1992. It was originally described in [#!shone:gb!#].
The approach taken is to (abstractly) model the processes involved in calibrating and imaging data. It should be pointed out that this approach has been somewhat controversial; for example see [#!flatters:rational!#]. An objection to the model as outlined in the original paper is that it was insufficiently data-centric and overly complicated. The present version of the model has evolved to at least partially meet these objections.
Data from a telescope is collected into a MeasurementSet. The telescope sampling process is described by a MeasurementModel, and the effects (primarily instrumental and atmospheric) which have corrupted the data are described by TelescopeComponent objects within a TelescopeModel. The goal, of course, is normally9.6 to produce the best representation of the sky as possible (usually in an Image, or possibly in a SourceModel) by correcting to the extent possible for the corruption and sampling processes.
Cornwell [#!cornwell:imaging!#,#!cornwell:telescope!#] developed an elegant mathematical formulation (informally called the ``A Matrix Formalism'') of the Green Bank approach to calibration and imaging. While this approach has not yet been developed further by the project, the approach is very interesting. In some sense, the (large) matrices in Cornwell's formulation have been replaced here by tables, and matrix operators have been replaced by operations on tables. (A table is of course one way to represent a very large, sparse matrix.)
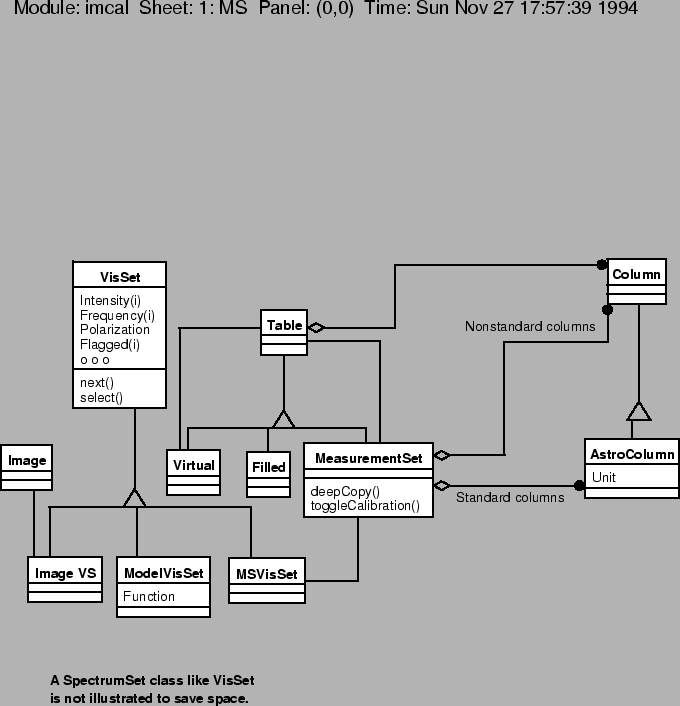
The MeasurementSet is the lowest level interface to data. The data might be either uncalibrated or calibrated (or partially calibrated). The MeasurementSet is intimately involved with AIPS++ Table objects, which are described in section 9.4. This close relationship is not accidental; Tables were of course designed explicitly to handle the processing of astronomical data.
It is intended that the MeasurementSet will hold not only the usual astronomical data, but possibly also data that is normally considered telescope monitor and control data (of course this isn't required, and the user might filter it out). This is to allow the user to make judgments about his data using all available information.
A MeasurementSet IsA table with certain conventions. In particular, there are a set of standard columns (e.g., effective integration time) which might be in a MeasurementSet. While a particular MeasurementSet need not have any particular columns, if it does have one of the standard columns that column must have its usual meaning. There are also a set of conventions that the standard columns obey, for example to associate units with the values in the column. In addition to the standard columns, the MeasurementSet might have other columns to represent some very telescope-dependent data, or even a column that a user has attached to hold some additional information.
It is important to note that the MeasurementSet is a single table, not a collection of tables. Other software systems have tended to separate things which vary at different rates (per observation, per source, per integration etc.) into different tables to prevent data bloat (caused by repeating constant values for several or many rows). Besides the navigational difficulties in finding the value that corresponds to the current row in another table, a more fundamental problem is that values can vary at different rates for different instruments (and observing modes), and hence finding a particular value might require a moderately complicated runtime lookup.
Instead, we have chosen to use the so-called ``big table'' view of data. This approach has all data appearing in a single table. This makes the navigation problem trivial -- all rows contain all values -- however it places a burden on the table system to provide a mechanism for avoiding unacceptable data bloat. See the section on table storage management (section 9.4.2) for details on how this is accomplished.
One often wants to query a MeasurementSet to discover what, for example, all the possible pointing centers are. This operation is less convenient with a ``big-table'' view when the underlying values truly vary infrequently. This may require optimizations or new functions in the Table system, or a caching convention in the MeasurementSet (for example, by using per=column keywords).
A MeasurementSet row is an important level of granularity. In general, a row of a table will contain:
The original concept was that each row would contain a truly atomic piece of information. This is conceptually attractive -- one does not have to worry about some members of, say, a visibility spectrum being flagged but not others. However, since this would place extreme demands on the table data system, we have decided to make the atomic unit the vector of data. Note, however, that we have, for example, separated separate polarizations onto separate rows (logically; the underlying storage manager might actually store visibility data as a brick when the number of channels, baselines, and polarizations are the same for all times).
When data from several different observations are to be combined, the data would appear in a single MeasurementSet, with a column to make unambiguous which instrument a particular row comes from. The columns in the joint MeasurementSet would be those which are common to all the MeasurementSets.9.7
The MeasurementSet is a view of data. The data might consist of raw values read from disk. However, it might also consist of data which is being calibrated ``on-the-fly,'' or indeed the data is being entirely simulated.9.8 This is accomplished by both deriving MeasurementSet from Table for its interface, and by having it reference a table (which might itself be a virtual table) for its values. The mechanisms to enable this are further described in sections 9.3.1 and 9.4.1 below.
While the MeasurementSet is complete, it can be tedious to use, or at least overkill, for some applications. Thus we define abstract classes which define the interface we want for our application, and attach them to the data source -- normally a MeasurementSet (MeasurementSetVisSet) -- but possibly also a function (ModelVisSet or image (ImageVisSet). These classes are known as data views in that they don't contain any data on their own, they refer to data which is elsewhere. While there might be a wide variety of such data views, the two which have been identified to date are the SpectrumSet and the VisSet; the former consisting of image-plane spectra, and the latter of visibility spectra.9.9These data views would be constructed with various selection criteria, for example, to only return Stokes I.
While it is possible of course to construct many different views of data, the SpectrumSet and VisSet are chosen to be rich enough to implement an imaging algorithm after the data is calibrated. So, for example, the VisSet would contain at least UVW, Time, Antenna1, Antenna2, Flags and Weights, and Complex Visibilities. Also, the data view might have some convenience functions build in, for example, to shift the visibilities before returning them to the user.
The usual end result of as calibration and imaging process is an estimate of a sky brightness distribution in the form of a SourceModel and/or Image which the user then analyzes to obtain his science.
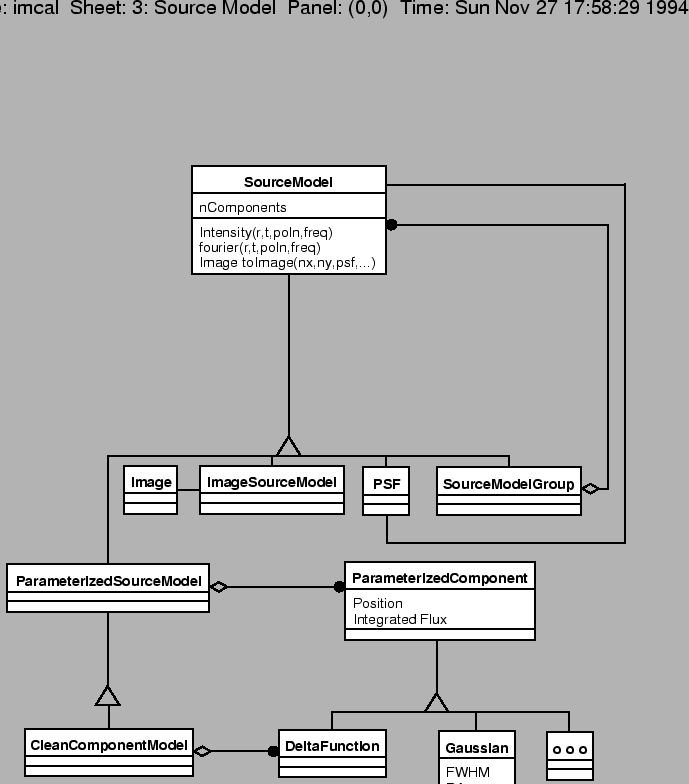
An Image is a regularly sampled set of intensities with coordinate information. It is described in more detail in section 9.5 below. The SourceModel is a more general description of the sky brightness distribution than an Image. Fundamentally, it returns an intensity as a function of position, time, polarization, and frequency. It is used to represent astronomical sources before observation, i.e., it is not convolved with a point spread function (PSF).
There are several different types of SourceModels. A ParameterizedSourceModel is implemented as a series of parameterized components. A Clean component list is a specialized version of this. An ImageSourceModel is one in which the components consist of the pixels from an Image. A SourceModelGroup is implemented with other SourceModels (in linear combination). So, for example, this could be used to combine an ImageSourceModel and a ParameterizedSourceModel.
Besides getting the intensity of the source model (in either the image or Fourier plane), a SourceModel may be gridded into an image (after specifying things like image size and point spread function).
The point spread function of an instrument is its response to a point source -- a delta function is the ideal point spread function. The point spread function might in principle be a function of time and position. Often, however, the PSF can be simply parameterized, or it can be represented with a single image. The same machinery that is used to implement the SourceModel can also be used for the PSF. For example, a ImageSourceModel could be used to hold a synthesized beam, a simple ParameterizedSourceModel could hold a single antenna beam, and a more complicated ParameterizedSouceModel (or a new derived class) could hold an HST PSF.
The SourceModel and PSF are astronomically distinct ideas. However it is not clear that the software difference between them (how the ``intensity'' is interpreted) Is large enough to warrant a new inheritance hierarchy. It is shown in figure 9.2 as a derived class. This relationship may be changed.
An Image will normally be associated with a PSF. The produces of the PSF needs clarification; it may be the joint responsibility of a MeasurementModel (``dirty beam'') and TelescopeModel (``primary beam'').
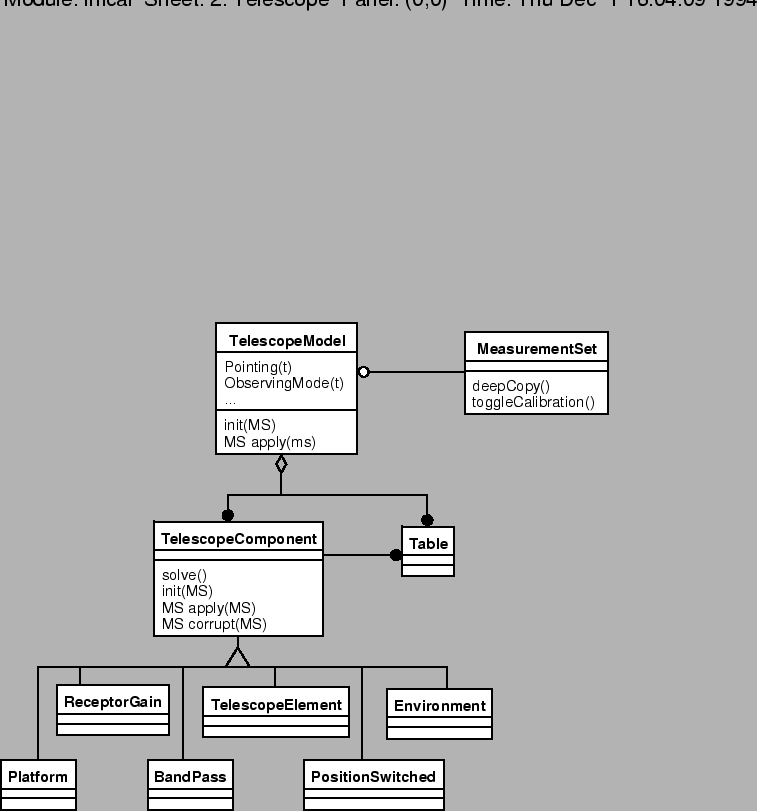
As previously described, a MeasurementSet might present data which is either uncalibrated (i.e., raw) or which has had some calibration applied to it. The TelescopeModel and TelescopeComponent classes implement this process.9.10
The TelescopeModel, as its name implies, is a software model of the real observing system; in particular how the observing system it corrupts the data. The goal is, of course, to correct the data as much as possible (or, occasionally, to simulate the effect of observations on perfect (simulated!) data).
Calibration is actually performed by a TelescopeComponent. The TelescopeComponent embodies a particular type of calibration; for example, a ReceptorGain would be used for an antenna-based gain solution, and a BandPass component would be used for squaring up the passband of the instrument. The TelescopeModel then consists of an ordered set of TelescopeComponent objects which apply their calibration in turn. To add a new type of calibration, one merely needs to create a new TelescopeComponent and slot it into the calibration chain. If the calibrations cannot be calculated independently, one merely creates a single TelescopeComponent in the place of those that are coupled; for instance, the Australia Telescope Compact Array (ATCA) performs the receptor gain, polarization, and bandpass calibration in a coupled fashion -- here one would produce an instrument specific TelescopeComponent which would replace the more generic versions.
So, the fundamental member function is apply (or its inverse, corrupt). For a TelescopeComponent, apply applies the particular calibration it knows about to a MeasurementSet. The TelescopeModel pushes a MeasurementSet through its active TelescopeComponents.
It needs to be emphasized that while apply logically creates a new MeasurementSet, normally the produced MeasurementSet will not make a physical copy of the data with calibration applied: instead, it will perform an ``on-the-fly'' (``on-demand'') calibration, referring to values in their original tables (although it is possible to physically apply the calibration and make a deep copy if desired). The mechanisms for doing this are described in the section on Table Data Management (9.4.2) below. Essentially, the Telescope merely needs to produce a new column which hides the old one, which in turn might be hiding an older one, etc., until we finally arrive at the raw data.
TelescopeComponent objects will in general have state associated with them; for example, a ReceptorGain gain component has a gain table: a table which contains columns of complex multiplicative gains which vary with time, a gain per antenna. Additionally, it will have state for things like interpolation policies.
This state needs to be initialized and updated. Generally the initial (default) values can be obtained from a MeasurementSet, so the TelescopeComponent has a method to initialize itself from a MeasurementSet, or the TelescopeModel can initialize all its contained components in turn. (Of course, the components state might also be set by the user in an ad-hoc way.)
There is, unfortunately, no way to set the ``solve'' (update) parameters in a generic way -- the operations in the particular telescope components are too diverse. Put another way, the user can use data without knowing precisely how it has been calibrated, but the calibration solution cannot actually be performed without the user specifying some calibration-specific information (in general; many particular TelescopeComponents, for example a single dish PositionSwitched telescope component, might be able to behave quite sensibly in a default setting).
When the solution information has been set (``associate this calibrator with those sources, use only long baselines'') solve itself may be called repeatedly (for example, in a self-calibration loop) to the extent that the parameters to be used during the solution do not need to be changed.
The TelescopeModel has two roles. The first, as described above, is to organize, and marshal data through, an ordered list of TelescopeComponent objects to perform a calibration. This function is reasonably well understood. Its other responsibility is to report on the state of the telescope in general (``where was I pointing at some time, where are my antennas''). In my opinion, the division of responsibilities between the TelescopeModel and the MeasurementSet are not clear in this respect and are in need of clarification.9.11
The MeasurementModel class encapsulates how a perfect telescope samples the sky producing a MeasurementSet, and the inverse process. The particular MeasurementModel will have assumptions and simplifications built into it; for example when imaging a small portion of the sky it might be considered to be flat.
The primary methods of a MeasurementModel are:
MeasurementModels might be quite complicated; for examples see [#!bh:exotic!#,#!cornwell:imaging!#].
The ``predict'' method is used in iterative calibration and imaging processes, like self-calibration. It uses the MeasurementSet to determine the locations at which to perform the prediction. The values in the original MeasurementSet might not be needed at all (the values from the SourceModel are used).
As presently formulated, image-plane corrections (e.g., primary beam) for interferometers would take place in the MeasurementModel, not in the TelescopeModel.
Fairly complete MeasurementSets have been written for single dish and the ATCA; only a very simple one for general-purpose interferometers has been produced. A combined general MeasurementSet for both interferometers and single dish is expected to become available at about the time of this writing (late 1994).
For single dish, a reasonably complete position switched telescope component has been implemented, along with an on-the-fly imaging application. The latter has not been integrated into a MeasurementModel. The next few months should see single dish work start to rapidly fill out.
The effort in interferometry has been largely dormant in 1994. A more active effort to implement core interferometric functionality will occur in early 1995.