News News |
FAQ
|
| Search
|
Home
|
| Getting Started | Documentation | Glish | Learn More | Programming | Contact Us |
|
| Version 1.9 Build 1556 |
|





Arrays have traditionally played an important role in scientific computation. While it is certainly true that some of the reliance on arrays was due to the paucity of other data structures in FORTRAN, it is also true that computation on arrays reflects the common occurrence of regularly sampled multi-dimensioned data in science. As a pragmatic matter, high performance computers often have optimizations (in the hardware and compilers) for array operations.
Besides arrays, there are other structures which have array-like characteristics. The most important for AIPS++ is the Image: typically a regularly sampled sky intensity in some polarization along axes related to position in the sky, and frequency.
This chapter presents a coherent set of classes and functions for computing upon arrays, images, and regular structures in general.
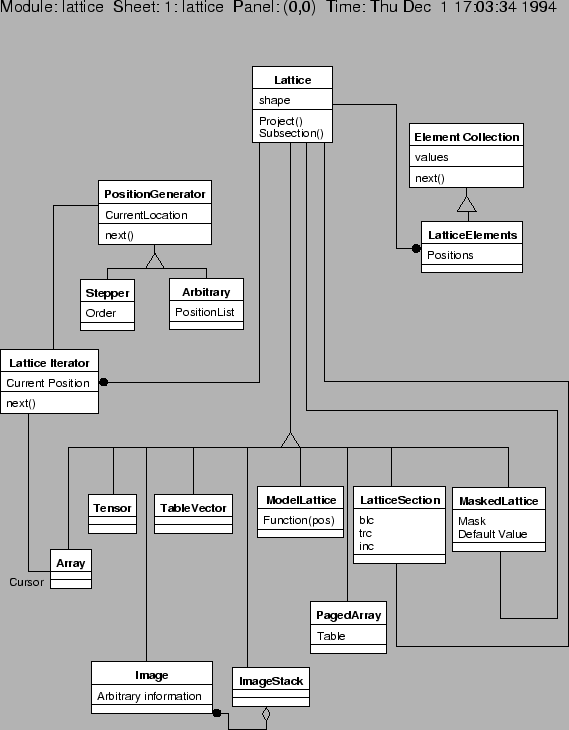
A lattice is an abstract base class which encapsulates a regular multidimensional data structure with a constant number of positions along each axis. The length of the axes, expressed as an ordered tuple of integers, is known as the shape of the lattice. Elements contained by the lattice are of homogenous type and may be placed into the lattice, or retrieved from it, at positions which correspond to intersections of the positions along each axis. A lattice contains a total number of elements equal to the product of its shape. Note however that it is not required that all the elements be distinct, for instance in a symmetric data structure changing one element may also change it at its mirrored locations.
The defining characteristic of a lattice is its shape. The fundamental operations on a lattice on a lattice involve setting and retrieving single elements, or collections of elements. The location of an element in a lattice is defined by a tuple of integers, giving the position of the element along each axis. This tuple is a class known as an IPosition (Integral Position). (Logically an IPosition is a 1D array of integers.)
An Array is a type of lattice in which all elements are unique and fit into memory. Moreover, the position of the elements in memory may be calculated solely from their position in the array; thus a sparse matrix implemented as run-length encoded lists of elements would not be an array in this sense.
It will often be convenient to have 1-, 2-, and 3-dimensional specializations versions of array classes to relieve the tedium of indexing arrays of arbitrary dimensionality, and to provide operations that only make sense for an array of a given dimension. Generally speaking, arrays opertions should be fast -- both for whole-array operations and individual element indexing.
Arrays play another special role in the lattice hierarchy. Often computations will be required on a regular set of elements from a lattice (``the m'th plane''; ``every i'th row, j'th column, ...''). These operations would be too slow if every element access required a function call; instead, the region is accessed through an array. That is, arrays give efficient access to elements from a regular section of the lattice.
Note in the figure (9.9) that a lattice is often associated with an other lattice, for example MaskedLattice. That generally means that the derived class is a view of another lattice. Moreover, since Lattice is a base class, implicit in this diagram is that the MaskeLattice might in fact be e.g., an Array.
Note also that all these classes are templated (also known as ``parameterized'' or ``generic'' classes in some languages). This means that the lattice classes are general containers, they may (in principle) hold elements of any type (however, all elements of a particular lattice are of the same type).
The simplest thing a user or client of a lattice might want to do is operate on some collection of elements from a lattice, where there is not (necessarily) any intrinsic regularity in the locations of the values. That is, there is only a ``next()'' function. An example for where this type of interface would suffice is calculating statistics, either on a whole lattice, or on some irregular set of points from it9.19 (for example, defined by a user selecting points from a GUI display of an image). In general, calculations which proceed ``element by element'' can use an element collection. In practice, this element collection is more like an iterator than a container class.
An element collection has no positions: it's merely a source of values (a linearized traversal). In fact, an element collection does not need to be attached to a container, it could equally well be attached to an input source.
Unlike an ElementCollection, the LatticeElements class has position from the lattice for each element. So, for example, if one is iterating through all the pixels of an image that meet some brightness threshold, one would know not only their brightness but also their location in the underlying lattice.
A LatticeSection is a view of a regular portion of a lattice. The portion of the underlying lattice which is being viewed may be described by a start, a length, and a stride along each axis. Note that a LatticeSection isA Lattice (it has a shape), and it also references an underlying lattice (that actually holds the values). The underlying lattice can of course be any derived lattice type, such as an Image.
A LatticeSection will normally be produced by one of the following:
Another useful type of Lattice is a MaskedLattice, in which positions are marked as either ``valid'' or ``invalid'' through the use of a mask.9.20 When elements which are marked as invalid are accessed, either directly or through an iterator, a default value is returned instead of the actual underlying value. In practice the most common default values are apt to be zero, or a not-a-number (NaN) value.
Masks can come from a variety of sources:
image(image > 5.0) = 5.0; // Clip
Another approach which is similar to this is to use ``magic values'' to mark the data as good or bad. That is, a special (``magic'') value is written into the lattice, and then various support functions look for that value.
We may want to implement magic-value blanking as well as masking. While less flexible, it is more efficient in space, and it irretrievably marks data as bad. A mask can be lifted off the data. While this is often desirable, it does lead to the possibility that invalid data might leak into computations. Of course, the data behind the mask could be set to a NaN value when this is a serious concern.
Very commonly, the most convenient method of computing on a lattice is to process it ``chunk by chunk.'' Common examples of this are processing a spectral line cube plane by plane -- each plane is an image at a particular frequency - or processing it spectrum by spectrum.
In AIPS++, we iterate through a lattice in this way by using a LatticeIterator. The lattice iterator has an array cursor (window) attached to it, which is scrolled through the image. The locations in the lattice that the cursor is filled from is defined by a PositionGenerator, which has at least two derived classes:
So, the cursor shape defines the chunks that the user is interested in, and the PositionGenerator describes the movement of the cursor.
One problem that occurs is an iteration which would extend the cursor partially beyond the edge of the lattice. There are (at least) three solutions that are appropriate in different circumstance, and hence the user must be given the choice of selecting the desired policy:
The cursor itself is an array. This provides both efficient access to the individual pixels, and provides access to all of the operations which are defined for arrays.
Note that this iteration abstraction is the I/O mechanism for lattices which do not fit entirely within memory (i.e., large images). The cursor is the ``I/O'' buffer, and the cursor shape and position define the disk head seeks required to fill it.
From time to time one will want to view a (multidimensional) function as a Lattice. For example, one might want to use image analysis and display tools on a simulation. While it would be possible to sample the function and use an array (for example), it might be more convenient (or efficient in space) to just use a ModelLattice -- a Lattice view of a function.
As described earlier in this section, Array classes are lattices in which all the elements are distinct and stored in memory. In a sense, an Array can be considered a multidimensional view of a chunk of memory which is inherently linear. In practice it, is convenient to have specialized Array1D, Array2D, and Array3D classes to allow, for example, more convenient (and efficient!) indexing.9.21
Logically the array classes need to be separated from the Tensor classes, which have different storage layouts (e.g., symmetries) than the Array classes, and different mathematical properties. Of course, some of these classes will use the corresponding array class for storage of the values.
In general, the Array classes are appropriate for applications like image processing, and the Tensor classes for linear algebra and related applications.
A PagedArray is a lattice which consists of unique values as with an Array. However, there are too many values for the lattice to be kept entirely in (virtual) memory, so a mechanism for staging values to and from disk (i.e., I/O) is required.
As with all Lattices, the user merely decides how he wants to iterate through the data. The actual I/O is performed by the table data system (section refsec:TableDataSystem). In particular, the actual data is stored as an indirect array in a column. Of course, that column will have an appropriate storage manager attached to it (Karma or AipsIO).
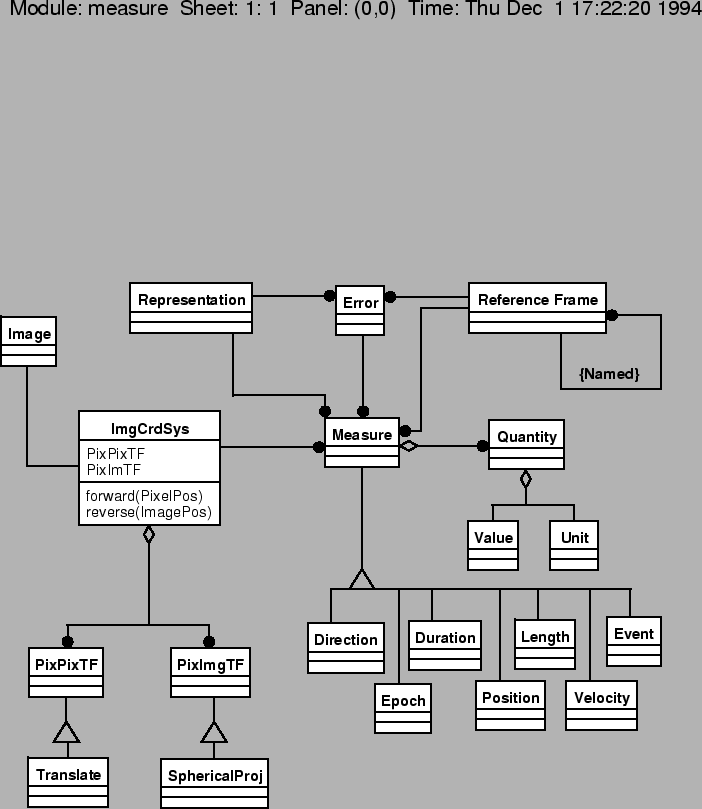
An Image in AIPS++ consists of a Lattice, which holds the pixel values, and an ImageCoordinateSystem. An ImageCoordinateSystem is an engine which turns pixel positions into real-world coordinates (and the reverse). While the Lattice Image is associated with will normally be a PagedArray, it might be another Lattice type. For example, a MaskedLattice which is in turn associated with a PagedArray corresponds to a Classic AIPS image with blanks.
In the past it has often been convenient for miscellaneous (``arbitrary'') information related to the image to be attached to it. This facility is also offered in the Image class, although we need to be careful that this isn't used as a substitute for designing and implementing appropriate classes. It uses the traditional keyword/value protocol.
One feature which has not presently been added to the image class if error estimates (or, alternatively, weights). It seems to this author that this is still a research topic -- simple independent, normally distributed, errors with the usual error propagation rules are apt to be very misleading. If, nevertheless, error estimates are required, I would suggest merely associating an error value with each pixel (behind the interface it might be subsampled to save on storage).
An image will normally have a processing log associated with it.
An image pixel's origin is at its center, not one of its corners. While there is no compelling reason for this convention, as discussed in [#!gc:fits!#] this convention has the nice feature that it is invariant to rotations.
A Measure is a base class that represents a physical measurement, for example Direction is used to describe a position on the sky. Every measure has a MeasureRepresentation which has the units of the physical measurement, and allows operations operations rotations. Every Measure also has an associatedMeasureReferenceFramd, for example topocentric vs. barycentric sky coordinates.
An ImageCoordinateSystem is used to tie pixel coordinates to their underlying Measure(s). More than one measure may be in an Image (Direction and DopplerVelocity most commonly). More than one image axis might be required for a given Measure (a Direction requires two, for example). The image axes for a given Measure may not be contiguous in the image (it might have been arbitrarily transposed). An AxisMapping is used to map axes to their appropriate Measures.
A pixel coordinate is turned into an image coordinate through a chain of PixelToPixelTransformations, followed by a single PixelToImage coordinate transformation. (Pixel coordinates may be non-integral, i.e., positions within a pixel may be specified). PixelToPixelTransformations will normally involve linear transformations (translation, scale, rotate etc.), however they can in general be also be nonlinear functions.
The final PixelToImage coordinate transformation does any final mapping (usually a spherical projection for a Direction), as well as associating the correct output axes with the correct Measures via the AxisMapping.
Note that if one wants (say) coordinates in an image reported in galactic coordinates rather than right ascension and declination, one merely changes the representation in the Measure. Similarly, if a change from a barycentric DopplerVelocity to one against the LSR (Local Standard of Rest) results from changing the ReferenceFrame.
The data values in the Image in principle also have a ReferenceFrame (so that one ccould apply a red-shift correction to the image through a change in ReferenceFrame). Initially the image may only attach units to the data values.
The Unit classes are used to represent physical units. Units may be composed ( velocity = length/time) multiplicatively, and unit arithmetic is supported (you can add furlongs to kilometers and get the result in parsecs). The Unit is normally part of the MeasureRepresentation, although it may also be used on its own.
It can be convenient to deal with a collection of similar images as a unit. The ImageStack class was invented for this purpose.
The rule9.22 which can be applied to determine whether or not an axis is a valid for an image, is that it must make physical sense to interpolate along an axis of that type. So, for example, a frequency axis is a valid axis, but a Stokes axis, or any other axis that is essentially an enumeration, is not.
An ImageStack is a collection of one or more images of the same size and with the same coordinate system. The ImageStack might contain Stokes IQUV images or it might contain the image at different stages of processing. Because the sizes and coordinate systems must be the same, features will ``line up.'' The fundamental operations on an ImageStack involve setting and retrieving images (``give me the `Q' image''), and getting the values of the images at some position (``What are the IQUV values at some interesting position on the sky'').
Note that ImageStack is inherited from Lattice, so that many image-like operations which only require pixel coordinates may, in fact, be carried out on ImageStack objects.
Besides the structures which hold and provide the access to data, powerful functions which act upon Lattices are also required for users to be able to concisely express the calculations they wish to be performed.
Fortunately, there have been a wide variety of successful languages9.23which implement such functions, so not much invention is required here. (As always, implementation can be tricky.)
Besides application-domain specific functions (gridding, FFT'ing, and the like), a powerful library of more generic functions is useful. It should include at least:
While an Image IsA Lattice, and hence all the Lattice functions may be called upon an Image, it will often behoove the user to use functions which are more Image-aware. Such functions might need to take into account:
A set of array classes have been available inside of AIPS++ for approximately two years. There is an N-dimensional Array class, along with 1-, 2-, and 3-dimensional specializations named Vector, Matrix, and Cube. As discussed above, these names should be changed to Array1D, Array2D, Array3D.
Lattice and Image classes have been available for a few months. The array classes have not been integrated with the Lattice yet, i.e., the array classes are not yet derived from lattice. However, there is a Lattice class which uses an array which allows much the same effect.
We anticipate writing a new set of array classes in the first half of 1995 to complete the merger between the Lattice and Array classes (and contains various small fixes that two years of use have turned up). The old classes will need to coexist in the system for some long time for backwards compatibility.
The LatticeIterator and PositionGenerator (with a stepper subclass) have been implemented.
The Array classes presently have whole array arithmetic and logical expressions. For example:
a = b + c*sqrt(d); // arithmetic
a(a > 5.0) = 5.0; // logicals
is supported. The corresponding operations for Lattices in general is
not yet supported. In other words, a fairly mature set of array
classes exist, but integration with the ideas outlined in this section
are required.
A somewhat controversial point has been whether or not lattices and derived classes should support variable (i.e., non-zero) origins. While they have been provided to date, on balance it seems that their potential for bugs outweighs their usefulness, and variable origins are deprecated and will eventually be removed.
Another controversial point has been whether or not operator* should perform element-by-element arithmetic, or perform a linear algebra multiplication (although a decision still would need to be made about inner versus outer products). This confusion was caused by the lack of separation between the linear algebra classes and the array classes. Array classes should continue to use element by element arithmetic, and the linear algebra classes should choose an appropriate multiplication to be performed by operator*.
Only trivial coordinates are available. Units classes have been submitted but are not yet in use.
While whole-array operations have been efficient, operations on arrays where a lot of array-indexing is done in loops is fairly inefficient. Presently the actual indexing of, for example, a Matrix is accomplished by code like the following:
T &operator()(Int i, Int j) { return data[xyoffset + i*xinc + y*yinc]; }
where xyoffset is related to non-zero origins, xinc is related to the
stride in x, and yinc is related to the stride in y and the length of
the x axis.
A sufficiently able compiler should be able to optimize (e.g., constant propagation) indexing when it is in tight loops. Many (not all) compilers in fact do not efficiently optimize such loops. Apparently they are unable to determine that the indexing constants are not aliased by the pointer ``data.'' Compilers seem to do much better in general when indexing is performed with an operation like:
T &operator()(Int i, Int j) { return dope[i][j]; }
So, if we want to make indexing more efficient we need to change the array classes in the following ways:
While our experience to date is that the effect of inefficient indexing is well confined in the code (e.g., inserting about 10 lines of FORTRAN made the Single Dish On-The-Fly imaging application run quickly enough) these changes are probably worth making.
A goal of AIPS++ is to allow the user to process image cubes without having to transpose them. For this to be realistic goal, the layout of the image data needs to be carefully defined. If it is done naively, processing a 256 x 256 x 128 cube ``spectrum by spectrum'' would result in 128 head seeks per spectrum, which would result in grossly unacceptable I/O behavior. To solve this problem, we rely on the Karma storage manager which can tile multidimensional lattice data.9.24
A problem under some circumstances are the creation of temporary objects. A delayed evaluation strategy might be attractive; it would also allow expressions to be analyzed so that, for example, a = b + c*d would only result in one loop, giving the optimizer more opportunities for optimization.