News News |
FAQ
|
| Search
|
Home
|
| Getting Started | Documentation | Glish | Learn More | Programming | Contact Us |
|
| Version 1.9 Build 1556 |
|





The discussion so far in this paper has mostly revolved around classes which are used to construct applications. Also important is the method by which applications interoperate with one another and communicate with the user.
Philosophically, the level of the AIPS++ system needs to be set. At one extreme, it is a virtual operating system which totally hides its users from the underlying OS, so, for example, users can process data on a Unix machine or VMS machine and not notice any difference. At the other extreme, one has independent executables which merely share a data format. AIPS++ is in the middle. It doesn't pretend to be an operating system (we don't have the expertise to write a very good one in any event), yet to allow for convenient processing, close communication between applications must be possible.
The goal of the AIPS++ runtime environment is to create, direct, and destroy entities which carry out radio astronomical calculations under both user and programmatic control. The runtime environment is not directly concerned with the nature of those calculations, however, it must be rich enough to support the required interactions.
It is assumed that the environment is typical of those on modern workstations (multi-tasking; the process is the normal level of granularity of computing; networked, hierarchical filesystems). We do not assume that the underlying operating system provides any object-oriented facilities.
The approach presented here is, while perhaps more flexible than a traditional package, still fairly conservative in the sense that it is readily implementable, and doesn't present a pure object-oriented approach at the system level. While I believe this is appropriate for us if it becomes inadequate other approaches are possible.
The AIPS++ runtime environment consists of asynchronously running processes running under the control of a control hub (which is itself a special process). All inter-process communication is conceptually through the control hub, although from time to time point-to-point communications may be obtained for efficiency.
A process will normally be playing one of several roles:
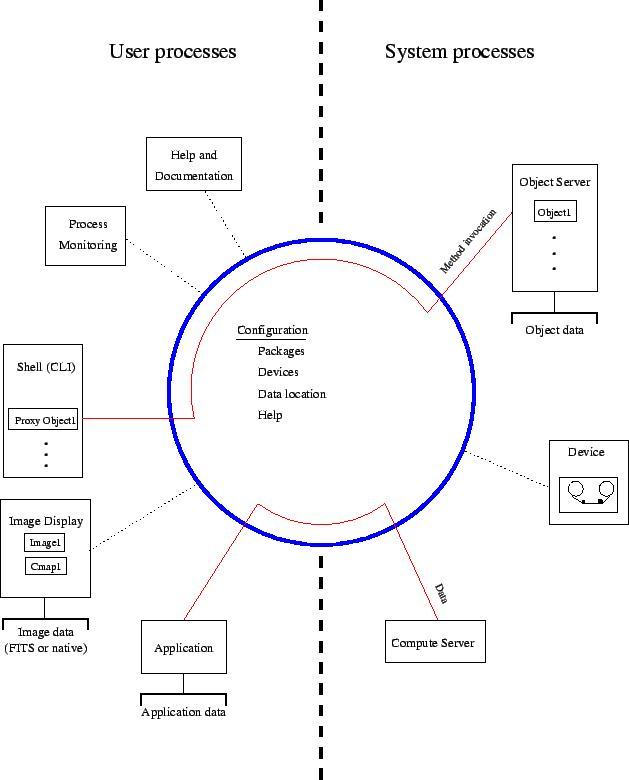
Figure 9.11 shows an example of what the environment might look like in practice.
The distinction between user processes and system processes is not a sharp one, however the user is likely to have directly activated the processes on his side of the line, whereas the system processes probably started at the behest of some other entity.
In the example, the user is directly manipulating an object in an object server through CLI manipulations. Those objects might be tables or images, or something less generic. Object servers will often need access to data (i.e., Tables), particularly if they are persistent.
The user has previously started some application which is presently communicating with some compute server (e.g., FFT). C++ applications would not normally use a compute server, applications written as a CLI script often will. Compute servers will often be stateless (pure functions), so they may not need a database.
A particularly interesting process is the image display process. It is both capable of displaying and manipulating images in a standalone fashion (at least FITS and AIPS++ native images), as well as accepting connections from other processes. For example, it might display an image sent to it, or give some other process a subregion of the image (for example, to compute statistics upon it).
Also attached to the control hub is a device interface process; these will be particularly important for tape drives. Also shown attached is a ``Help'' process9.25 and a process monitor (log messages, percent completed displays, and the like).
It needs to be stressed that the above roles are purely a convention. At the lowest levels we merely have inter-communicating processes. Layers above the system interpret whether a process is an application task, server, or proxy object server.
With this framework, a simple underlying mechanism will suffice; in particular a message passing client-server architecture should be sufficient. The role a process fills is then established by what messages the process responds to and emits at runtime. Note that this means a given binary executable file might be capable of producing processes which act as both servers and tasks (which role for a given process would normally be deduced from command line arguments).
Every process has a name, a typelist, and an address (``ID''). The name is an appellation for the process. It will typically be the same for all processes from a given executable, although it may in principle be picked (or even changed) at run time. The ``typelist'' is a set of ``types'' that this process considers itself, and it will respond to broadcasts that correspond to any type in its list. The address is used to direct communications; it is very implementation specific. It is unique for every process.
The messages themselves consist of a message type, and a set of keyword=value pairs. The message-type is used to show whether a given message contains task parameters, distributed object method-invocation parameters, a log message, etc. The values will consist of at least all the usual scalar types, arrays of scalar types, a ``null'' (unset) type, as well as sets of keyword=value pairs. The latter makes it a hierarchical structure.
It will take some experimentation to discover when to send data by value (i.e., stuffing the actual values into messages) or by reference (sending a ``file name''). Generally, when the receiver might only want an unknown subset of a large dataset or when efficiency is paramount, sending by reference is probably appropriate. In any event, point-to-point communications should probably be enabled before sending extremely large messages.
This design is at least partially chosen to be readily implementable in Glish. It is not, however, a direct correspondence; in particular the notion of broadcasts and a typelist will need to be layered on top of Glish (described below).
If the underlying processes merely are asynchronous entities which are capable of exchanging messages with one another, conventions need to be built which define the responsibilities and message protocols that different classes of processes understand.
The architecture is considerably simplified if an overall controlling and organizing process (per-user, per-machine) exists. We call this special process the control hub.
While the existence of a control hub is a ``single point of failure'', the simplifications in design and implementation it affords make it a worthwhile one. Many computational tasks and other tools (particularly GUI display tasks) can operate quite successfully without communicating with other processes. These processes should have a standalone mode where they can run independently.
Aside from the role of the hub as described above, a philosophical point can be made. Experts will write the hub and control its evolution. Applications will often be written by naive programmers. If there is a choice of where to put complexity -- in the process or in the hub -- it should go in the hub.
It is probable that various kinds of functionality not presently envisioned will be required in the future. Having a control hub which is itself readily programmable will greatly ease the burden of providing additional or different functionality in the future.
The control hub maintains a list of active processes, including their name, typelist, and address. Processes communicate by exchanging messages. Messages may be sent at any time, although whether or not it ``interrupts'' the recipient process depends on whether that program wishes that sort of interaction. A message may either be sent to a particular ID, or it may be broadcast to a typelist. Messages which aren't received immediately are queued in the hub.9.26
For efficiency, a process may request a direct point-to-point connection to a particular address. Messages to other addresses and broadcasts are not possible until the point-to-point connection is broken. (This might be unnecessarily restrictive.) The sender will probably also block in this circumstance.
The hub keeps a list of all active processes and related information in an active process list. For each process, the hub records at least:
A group of processes may be indicated by either of:
The active process list can be requested by a process via a message to the hub. The requestor may define a group of processes of interest or it may request the entire list.
Other messages related to control of processes that the hub will respond to include:
This information is cached by the hub so it doesn't need to regenerate it each time (which might consist of running many executables).
The hub will respond to certain messages to display the list of packages, available binaries, etc. This can be used by humans to browse the online set of available functionality. The hub will also respond to messages telling it to update its package cache (e.g., an executable is added or changed; timestamps can be used to determine which executables and directories need to be examined).
Until such time as we have language support for making objects ``distributed'', creating a distributed object will require some binding process. This binding process must not be so painful that it is not carried out for important classes.
There are various reasons why we need distributed objects. Perhaps the most compelling reason is to allow users at the command line to take advantage of functionality in the library. Without access to this functionality, the CLI user would only have limited access to functions compiled into the library. Whether a given piece of library functionality should be bound as a simple computation server or as a distributed object, of course, depends on the complexity of the operations. An FFT can likely be a simple compute server; a Table object should appear in an object server.
A related reason is to allow for introduction of new derived classes at run time without forcing recompilations. Take the case of tables: a lot of effort has been spent to allow users to derive new types of tables (so-called virtual tables). Suppose a user creates a new type of table and then wishes to display that table with the table browser. If this is to occur without the table browser being at least relinked (and probably slightly modified), a facility like that offered by ``distributed objects'' is necessary.
Another use is to allow computation to be farmed out onto separate machine(s). For example, cleaning a spectral line cube in parallel, one plane per machine.
To reiterate, there are two main uses for a distributed object:
The fact that an object is distributed is an implementation detail to the user of that object, at least after it has been constructed.
To create a distributed object one must:
This section discusses persistence in general, as well as catalogs. It has to be realized that the general persistence problem does not have to be solved from the beginning. It will suffice for some time to be merely able to store high-level astronomical objects (image, visibility dataset, etc.) as well as tables and groupings (associations) thereof.
Persistence is the ability to reform an object into a running process from data on some storage medium (i.e., normally disk). A somewhat subtle distinction can be made between persistent values9.27, where a new object contains the values (i.e., state) of some previous object, and persistent objects9.28, where the same object is considered to survive multiple invocations in different processes. Ideally a persistence mechanism is easily extensible to handle new classes. It may well be that practicality requires us to stage the implementation of persistence in two stages; the first of which only handles a few predetermined classes.
A catalog is a structure for organizing collections of persistent objects. It also normally contains additional information so that a user may browse the catalog to select objects to be used in further data processing.
An association is a grouping of related objects. This is somewhat different than merely making persistent an object that has ``pointers'' to other objects. An association will often be made or broken by users through the CLI. One particular object of an association is normally considered ``primary.'' Hierarchical associations should be supported.
While the general problem is very difficult, it is considerably simplified if one only needs to be able to use such an object polymorphically through a base class that was available when the executable was linked. A (fairly) simple strategy that would suffice is to create an inherited class that talks to some object in a server. In this implementation, if a class wasn't available when a particular executable was created, you can still access it via IPC to some object server (at some loss of efficiency) through the hub.
Another possibility would be to use dynamic linking, but that is less portable.
How do we handle versioning?
Concurrency. One thinks of persistent objects living in one process at a time. People are used to, say, having one ``writer'' of a data-set (i.e., object) but possibly many readers. Is this consistent?
Answers to these questions are likely to be strongly influenced by implementability considerations, i.e., simple.
The command line interpreter has to serve both the modest user who only wants to run pre-written tasks, as well as the user who wants to do powerful interactive manipulations of his data and write new applications in a very high level language.
To be a useful GUI, the language must both have a reasonable syntax, and must allow access to high-level operations. For the latter, having a language with ``whole-array'' expressions (as in languages like FORTRAN 90 or IDL) is a very good start. To have a yet more powerful CLI requires that the types of domain operations encapsulated within the library be available through the CLI. Thus a mechanism for readily binding new functionality from a library to the CLI is important to allow CLI programmers to be ``first-class'' programmers, i.e., to give them the same sorts of tools that are available to the programmer of the compiled language. The CLI should in fact be the most flexible possible interface to the libraries of the system.
It is important to note that the CLI is distinct from the control hub. In principle the CLI is readily replaceable (alternatively, a choice of CLI's might be available). Additional CLI's merely have to be able to send and receive standard messages to and from the control hub.
There are several different ways that GUI tools or components from GUI tools might be useful:
There is a variety of additional centralized functionality that the control hub provides access to. This list will undoubtedly increase with time.
Glish has been adopted for the control hub, and sample computation servers and proxy object servers have been implemented. Glish event conventions are still informal. Presently Glish can only communicate with processes which it has started. Partly because of this, the clean separation between the hub and the CLI has not yet been made (this problem may be solved by a non-AIPS++ Glish developer, otherwise we shall have to do it ourselves). Proxy objects have only been written in Glish, not C++, to date.
Glish has been augmented for use as a CLI by adding N > 1 dimensional array and complex data types, and by adding command line editing.
Persistent values are only implemented for a few important types. There is no catalog classes yet, we are using the unix file system.
A GUI table browser is available. It does not yet show table keywords, nor does it allow the table values to be modified. Two independent GUI graphics tools are being developed; at least one of them is capable of being ``programmed'' via Glish events.
Some classes to isolate OS dependencies have been developed. More are required.